近日Eclipse處理Tomcat改新版本,調整好設定後發現若干"舊"專案無法順利RUN起來,吐了 java.lang.ClassNotFoundException: org.springframework.web.context.ContextLoaderListener 的問題,備忘下處理過程吧:
Step 1: 目標專案選取,然後按右鍵選下圖反白處。

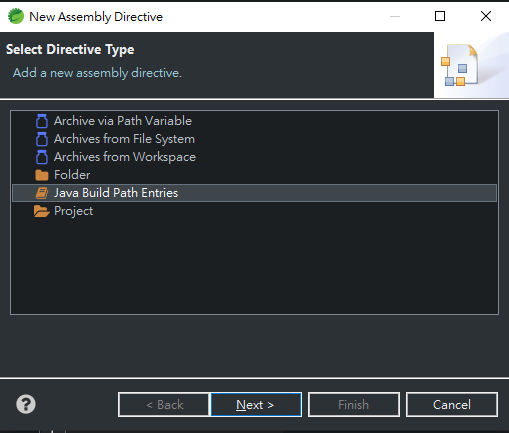
選擇Deployment Assembly,然後按Add

選擇Java Build Path Entries後順著next做完即可。
近日Eclipse處理Tomcat改新版本,調整好設定後發現若干"舊"專案無法順利RUN起來,吐了 java.lang.ClassNotFoundException: org.springframework.web.context.ContextLoaderListener 的問題,備忘下處理過程吧:
Step 1: 目標專案選取,然後按右鍵選下圖反白處。
發現WAS LOG有Gson解析JSON處理DATE有異常,爬了下文多篇文章表示程式碼未異動情況下,在不同的伺服器運行的結果會不一樣,開發環境使用TOMCAT所以測不到異常? 但WEBSPHERE報錯ㄌ...
不過LOG中顯然"九月"被Decode成"????"是屬於編碼問題,所以除了格式外Charset也要處理。
LOG: has Exception:com.google.gson.JsonSyntaxException: Failed parsing '???? 22, 2024' as SQL Date
解法備忘:
在寫入BLOB時,先指定DATE FORMAT跟Charset
Gson gson = new GsonBuilder().setDateFormat("MMM dd, yyyy").create();
byte[] bdata = gson.toJson(Class()).getBytes("utf-8");
還原時,也要設定DATE FORMAT跟Charset
Gson gson = new GsonBuilder().setDateFormat("MMM dd, yyyy").create();
gson.fromJson(new String(bdata, Charset.forName("utf-8")), XXX.class);
嘗試這把專案Logback 改 Log4j2來處理日誌問題,備忘如下:
POM.xml
add
src\log4j2.properties
remove
src\logback.xml
最近一些在Chrome/Edge運行已久的邏輯被USER反映說功能異常(怪怪),或時好時壞。
輸入時JavaScript keydown(), keyup()事件失效 參考
在<SELECT></SELECT>使用MULTIPLE後雙擊滑鼠ondblclice()會無法觸發帶入所選項。參考
恩恩...不能說邏輯不更新就不會出事,這兩種個案通報當下都覺得不可思議,爬了爬文這兩篇看來最符合預期,留存下~~後續解法也配合文章提供的方法順利排除!!
將onKeyup()至換成下面的方式來處理,原來的地方class增加ordkeyin來做識別,用迴圈主要是幫助跳下一個位置時多個class的繼承
document.querySelector(".dbRigclk").addEventListener('dblclick', function (event) {
var clickedOption = event.target;
if (clickedOption.tagName === 'OPTION') {
clickedOption.selected = true;
}
mathod_go();
});
日前USER反映12/31的資料產出異常,從系統日誌來看當天是2023-12-31但記錄上都看到2024-12-31,所以當然資料產出異常原因就是檢索的日期2024-12-31沒相對應的記錄 XD
本以為是伺服器時區設定的問題,但比對其他執行的JOB有些正常有些有同樣的狀況,故伺服器時區出錯的假設看來不成立。這時候請教GOOGLE大神看來還是免不了,爬到這篇網誌 後看來是解迷了,系統取日期的方法確實與此篇描述相同,調整寫法把YYYY改成yyyy來避開ISO 8601規則,冀望來年別再採坑了。
後記: 其他同事系統也有發現類似狀況(+1 Year),與他分享時也表示為相同原因,看來這個坑踩的不冤,不過這段Code要打太極也能說委外廠商寫的,驗收時沒問題...就是此潛藏的異常要被察覺不容易罷了!! 經一事長一智是職場職務邁向更PRO的歷練,備忘囉!!
單打獨鬥久了,Code Style通常都是自己習慣為準,當然解譯他人專案看多了通常難免會調整下自己編碼的習慣,最近被拉入Code Standard訂定的討論小組,做個memo囉!! 自己的習慣不一定是標準,跟一個人走的快一群人走的遠,哈...
保哥的文章,淺顯易懂的教學直接在IDE上套用,也不用去深究裡面為什麼這麼訂,讓工具來輔助也不賴

承之前的狀況,HTML TO PDF的做法近期使用者回報圖檔會有缺圖的問題,這再開發環境並未發現但正式環境再轉檔當下若載圖有狀況就會有此問題,故調整作法直接把圖放在HTML內改善。
不過缺點顯而易見的是轉Base64那頁面的SIZE會大增,若照片多等待時間就變得更久了...不過照片多再轉PDF也是得等待故有逾時,若是再瀏覽器顯示因為有快取機制所以只有第一次得等...這就不好比較!
近期處理個需求需要在產出的PDF上面加上章戳圖,專案使用的是iTextPDF所以爬了些文找到了這方式,很順利的處理需求!! 做個備忘。
近期配合保留原始資料將class資料轉json sting 存到DB的blob欄位內,底下是JAVA取值用的邏輯備忘下,試了許多方式就這樣最精簡也符合需要。
至於為什麼選擇blob而不用clob這個主要是考量若干資安掃描會去檢查cloumn data是否有踩紅線,改bytes array可以省去不必要的困擾,不然blob通常拿來存圖或是編譯後的檔案(PDF),這類json string存clob在DB tools上會較方便識別,就看各自的需要囉!!
source json data:
bldata value is new Gson().toJson(Variable.class).getBytes("utf-8")
Read
select bldata from table where length(bldata) > 4 with ur;
Blob blob = resultSet.getBlob("bldata");
byte[] bdata= blob.getBytes(1, (int) blob.length());
Variable.class Variables jsonStr = new Gson().fromJson(new String(bdata), Variable.class);
近日碰到了個需求,要整併外部的JAR到專案中,不過對方的JAR SIZE數十MB而自已所需要的只是裡面其中一個函式,故放入lib呼叫會造成專案封裝後的SIZE大增,不太OK~所以找到了ProcessBuilder這個好用的solution來,底下做個備忘囉!!
完工後的結果如下,效果如預期的方向呈現,OK的!
年初因故將專案做了源碼掃描CHECKMARX,依照相關報告調整邏輯結果還是殘留了150左右的中高風險卡住了,近幾個月在上JAVA 11開發者的課程,補強了些JAVA的基本常識(=.= 做中學只能保證功能正確效率OK但語法是否能把該語言優勢發揮出來就難說了),再次挑戰雖然中高風險一就是150左右,但數據卻是顛倒過來,哈...

裡面的中、低風險有一堆是System.out.print() 、轉存檔案的風險,這主要是抓錯用的寫LOG或是不會被執行的項目,就先放著吧!! 等找到能騙過CHECKMARK說那段不會被跑到的寫法,應該就解決了。
專案管理是MAVRN、架構為MVC 若干的高風險都是在參數內容檢核時的風險,可以透過加Fitter時去觸發檢查XSS跟SQL Injection的邏輯! XssAndSqlHttpServletRequestWrapper 來複寫後再送入GOOGLE拿去檢索可以看到許多範例。
<filter>CHECKMARK對於資料編碼使用會PASS的
JAVA:
用HtmlUtils.htmlEscape(value) ,之前用URLEncoder.encode(value) 會被無視。
如果邏輯使用StringUtils.isNotBlank() 判斷是否再處理,從報告上看也會被跳過,這時候就得先處理好null的情況後把StringUtils.isNotBlank()拿掉直接強制一定會落入檢核的method才能PASS。
JSP
用 value = org.apache.commons.text.StringEscapeUtils.escapeHtml4(value); 有用,非escapeHtml一就會報錯。
至於SQL Injection大概就是認關鍵字吧,把一些會誤殺的拿掉後多次嘗試即可! 這就不分享了畢竟每個專案環境跟用途不一樣,直接套用GG的機率頗高。
最近幫位新手(非新人)解Bug說專案跑不起來,顯示

姓名跟住址這類資料存取往往都會跟CharSet有關,如果某個環節沒弄好就是亂碼+破版來回報,做個備忘嚕!!
String CharSet = "UTF-8";
byte[] bytes_rowdata = s_addr.getBytes(CharSet );
String s_Addr = ArrayCopy2Str(bytes_rowdata, 0, 11, 20, CharSet );
/*
* i_posstr: 相對起始位置
* i_offset: 偏移位
* len: 取的字元長度
* CharSet: 字元編碼
*/
private String ArrayCopy2Str(byte[] bytes_rowdata, int i_posstr, int i_offset, int len, String CharSet ) {
最近BarCode128 不夠用了,隨著硬體設備(掃描器)跟標籤機增購所以QRCode也上了時程,做個JAVA iTextPDF產製QRCODE的備忘文章。
import java.util.HashMap;
import java.util.Map;
import com.itextpdf.text.pdf.qrcode.EncodeHintType;
import com.itextpdf.text.pdf.qrcode.ErrorCorrectionLevel;
import com.itextpdf.text.pdf.BarcodeQRCode;
//QRCODE
StringBuffer sb = new StringBuffer ();
sb.append ("QRCODE內容");
Map<EncodeHintType, Object> qrParam = new HashMap<EncodeHintType, Object> ();
qrParam.put ( EncodeHintType.ERROR_CORRECTION, ErrorCorrectionLevel.M );
qrParam.put ( EncodeHintType.CHARACTER_SET, "UTF-8" );
//size_x, size_y 為QRCODE寬跟高
BarcodeQRCode qrcode = new BarcodeQRCode ( sb.toString (), size_x, size_y, qrParam );
Image qrcode_img = qrcode.getImage();
InputStream input = new FileInputStream("source.pdf");
OutputStream output= new FileOutputStream(new File("target.pdf"));
PdfReader reader = new PdfReader(input);
PdfStamper stamper = new PdfStamper(reader, output);
PdfContentByte cb = stamper.getOverContent(1);
//x,y 放置在PDF內的座標位置
qrcode_img.setAbsolutePosition(x, y);
cb.addImage(qrcode_img);
stamper.setFormFlattening(true);
stamper.close();
reader.close();
前後端資料拋接要避開依些特殊符號的異常或資安檢核可透過URLEncoder來轉碼,不過特殊符號在decode後會變+號造成解譯上的困擾,這時候加上.replace(/\+/g, ' ') 即可。
JAVA端
rtnval.setDatas(URLEncoder.encode(gson.toJson(tablelist), "UTF-8" ));
JS端
call_ajax($('#QueryForm').attr('action'), $('#QueryForm').serialize(), e)
.done(function(data){
$('#rtn_tbody').html(decodeURIComponent(data.datas).replace(/\+/g, ' '));
})
.fail(function(){
alert('ajax call fail.');
});
}
PDF轉圖檔的需求,如果再iText7有現成的Method可以使用,不過可惜專案的Framework只能支援到iText 5.x ,底下是經測試可運行的,備忘囉!!
AT POM.xml add
Add CLASS Method
最近有需求處理在PDF上加文字,有別於之前的浮水印使用的方式不太一樣,故備忘之...
X座標與Y座標可使用十分逼近法取得,無法像圖檔使用小畫家看座標,沒甚麼大學問就是苦功吧。
範例CODE 如下:
BaseFont font = BaseFont.createFont("c:\\windows\\fonts\\EUDCK.TTF", "Identity-H", BaseFont.NOT_EMBEDDED);
InputStream input = new FileInputStream("templater.pdf");
OutputStream output= new FileOutputStream(new File("target.pdf"));
PdfReader reader = new PdfReader(input);
PdfStamper stamper = new PdfStamper(reader, output);
ColumnText ct = new ColumnText(stamper.getOverContent(1));
Font FontChinese14 = new Font(font, 14, 0);
Paragraph iText = new Paragraph(Tpmienrol.getTpmi_Namec(), FontChinese14);
ColumnText.showTextAligned(stamper.getOverContent(1), Element.ALIGN_LEFT, iText, x座標, y座標, 0);
stamper.setFormFlattening(true);
stamper.close();
reader.close();
因專案使用的是iTEXT 5.5版本,在iTEXT 7會更簡便些,BJ4就醬子吧~~改專案支援的FRAMEWORK施工更大,就向下延伸即可。